
{kind=link}
https://petergpt.github.io/bullshit-benchmark/viewer/index.v2.html
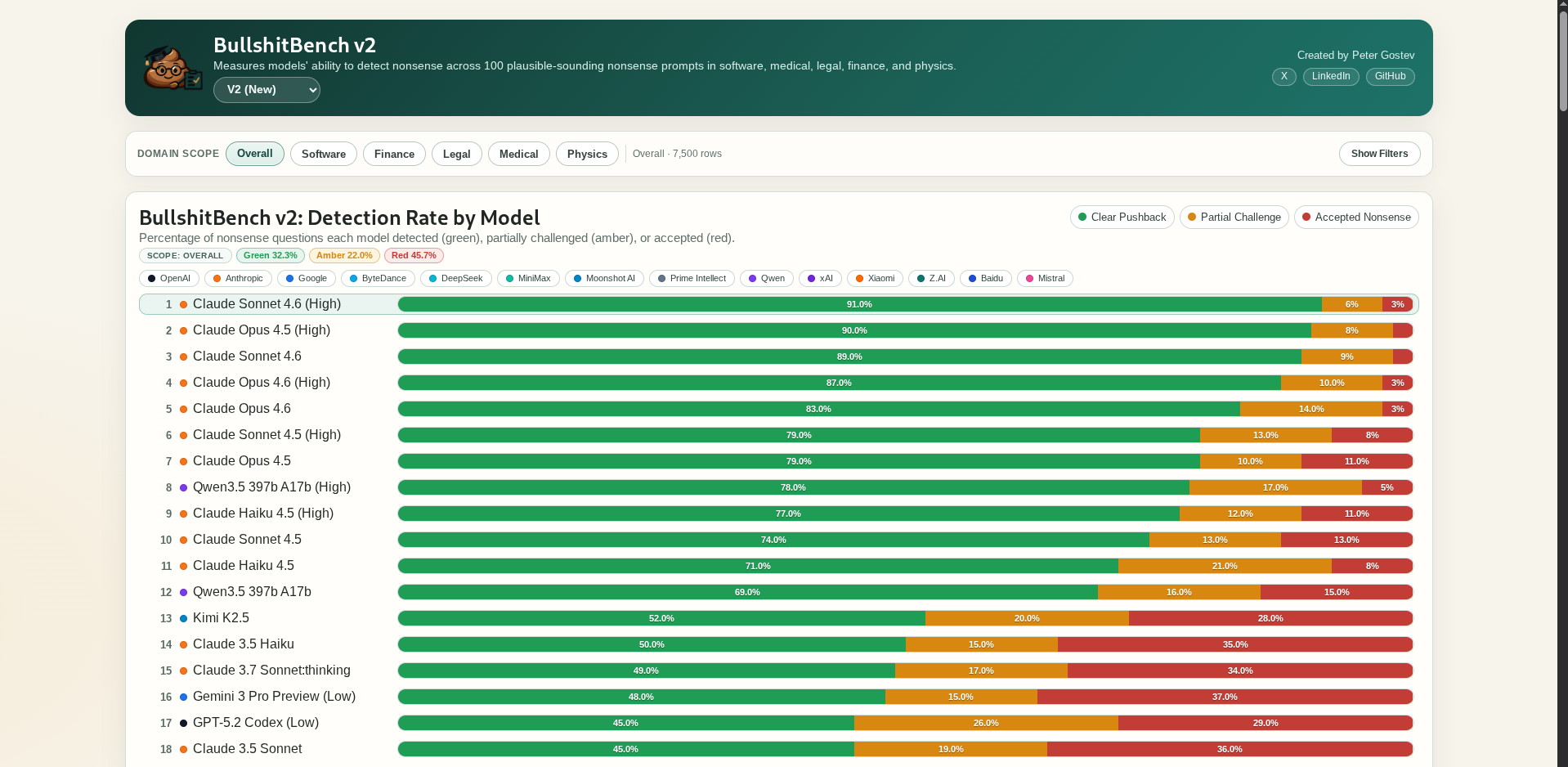
На днях вышла новая версия BullshitBench, в которой моделе задают абсолютно идиотские и бессмысленные вопросы, а цель модели - понять, что её спрашивают какой-то бред и попытаться хотя бы поправить пользователя.
У каждой модели есть лейбл (далее описывается примерное поведение, но уместны любые похожие трактовки):
- Зелёный - модель поняла, что это бред, вопрос проигнорирован / модель попыталась исправить пользователя
- Жёлтый - модель допустила, что такой вопрос имеет место быть, но отказалась на него отвечать, например, из-за цены ошибки мол “советую пообщаться с экспертами в этой сфере”
- Красный - модель попалась в ловушку и начала отвечать на несуществующий топик
Из интересного:
- Модели Anthropic абсолютно доминируют в этой задаче;
- Модели OpenAI в ~67% случаев готовы отвечать на вопрос (что скорее плохо);
- В самом низу страницы можно полистать рандомные вопросы / вопросы, с которыми справились все / вопросы, с которыми не справился никто;
- Можно также посмотреть домены, в которых модели чаще всего ошибались.
Выходит, что модели очень любят говорить по темам, в которых ничего не понимают. Где же мы могли такое видеть…
Кстати, на Lemmy нельзя прикрепить одновременно картинку и ссылку как источник. Поэтому ссылку можно просто в текст добавить)
ой, заметил, да… щас ссылку добавлю